


Adam Awale, On-device research, AGI Inc., PhD candidate.
An inference engine is the software that runs a model on a device: it takes the model and maps it onto the chips the device actually has, the CPU, the GPU, and increasingly the NPU. We built our own, AGI-RUN, and benchmarked it on a Samsung Galaxy S25 Ultra against six small vision-language models from the Qwen, Gemma, and Liquid families.
We compared it three ways:
Most of the numbers below measure prefill. We focus there because edge workloads are prefill-heavy by design: on-device, decode is slow, so the workloads that matter read a lot and generate little.
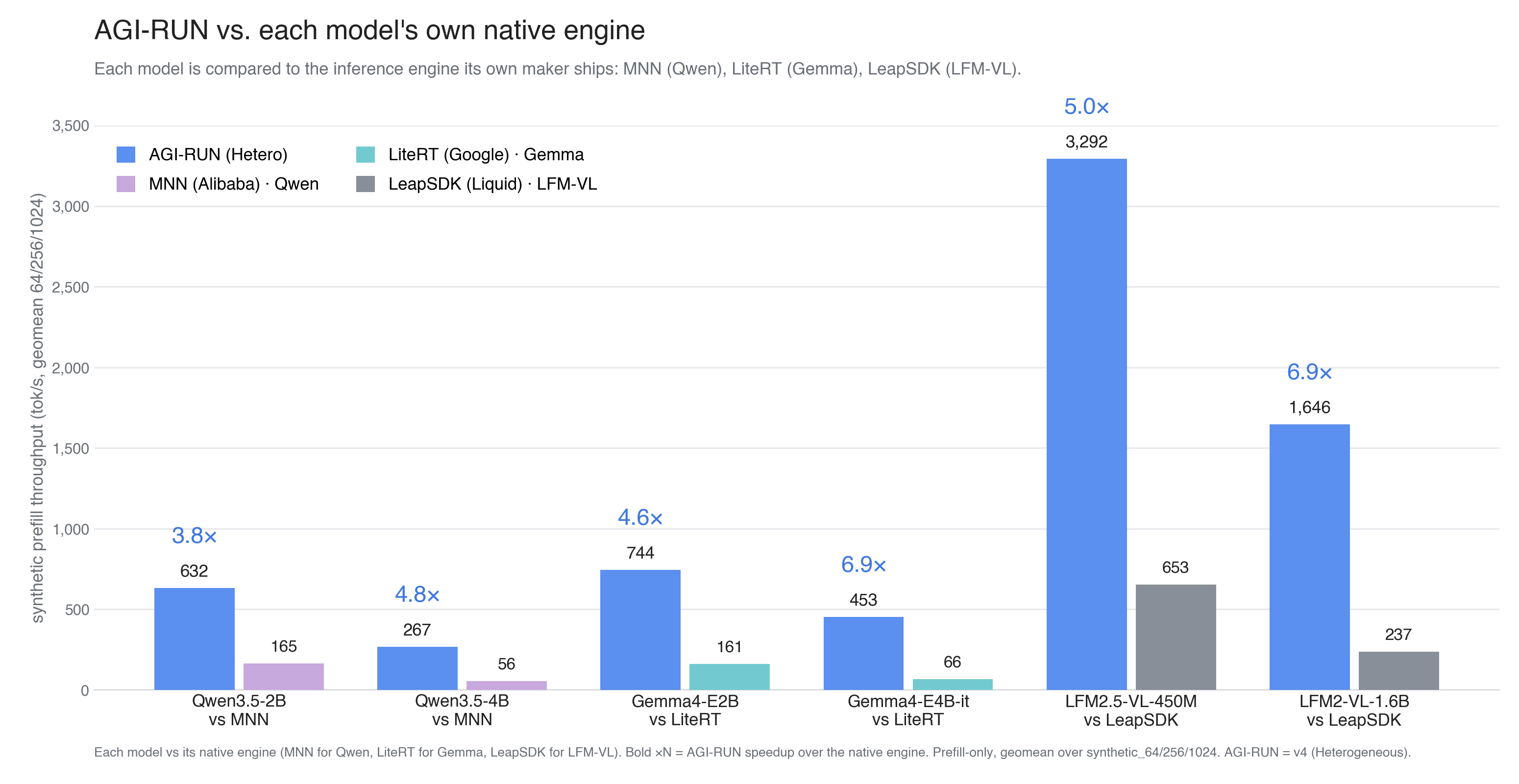
The hardest test is each model's native engine, the one its makers built or expect it to run on: MNN (Alibaba) for Qwen, LiteRT (Google) for Gemma, LeapSDK (Liquid AI) for LFM. We beat every one. AGI-RUN is ~5× faster on average, up to 6.9×, and the advantage grows with model size (4.8× to 6.9× on the larger Qwen and Gemma variants), because bigger models are more memory-bound, and our approach is built to use that memory efficiently.
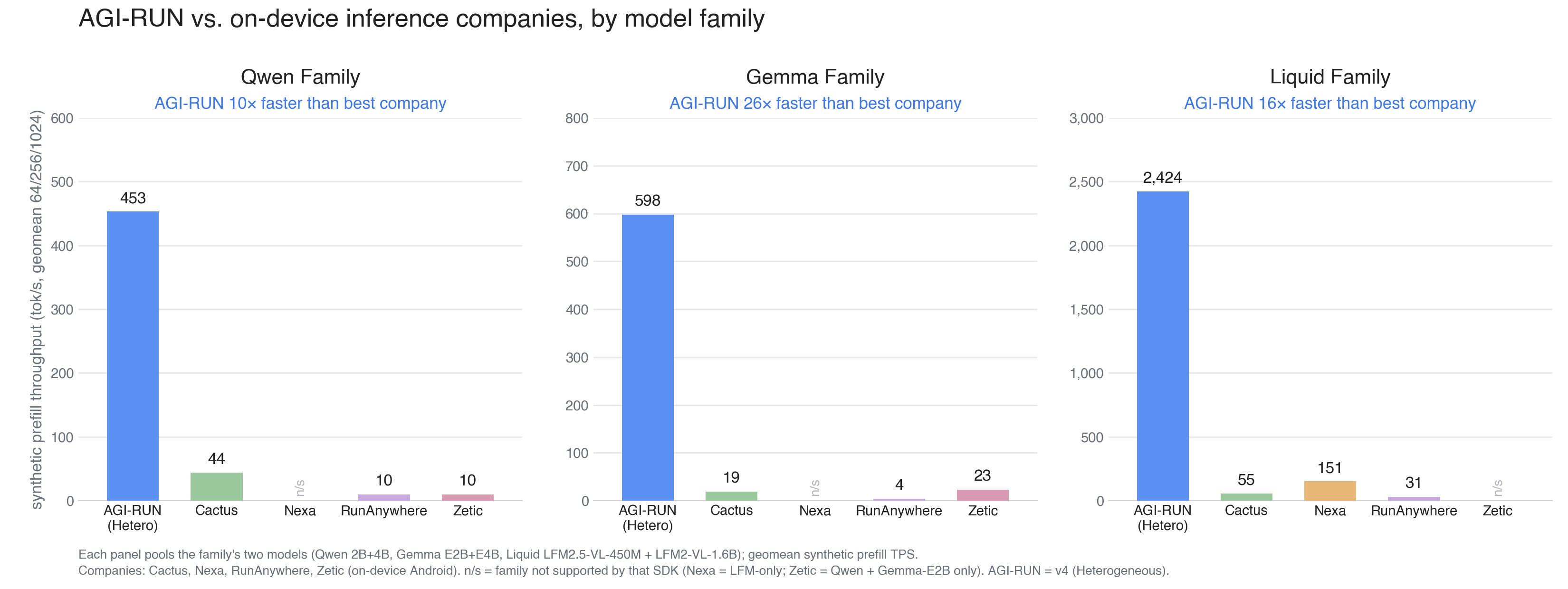
Next, the startups selling drop-in inference SDKs to app developers. The gap is not close (tokens/sec, higher is better):
Two things stand out:
We run all six, and the reason is architectural. Most engines dispatch each operation to a per-operator kernel library, so the day a model ships an operation that library doesn't have, it simply won't run. We build on low-level hardware intrinsics, the device's own instruction set, and let our cost models map the whole workload onto it. There is no unsupported-op wall, so we cover every model instead of only the ones someone hand-tuned for.
Across the full field of SOTA frameworks (llama.cpp on CPU, GPU, and NPU; MNN; MLC-LLM; LiteRT; mllm), run over six open source text and image datasets, AGI-RUN wins 58 of 60 model-and-workload cases, at a geomean of 3.3× over the best rival in each one, up to 9.9×. It is also the only engine besides llama.cpp and MNN to run every case; the others stall on model families they weren't hand-tuned for. The full per-case table, and how we get these numbers, is coming soon in a technical deep dive.
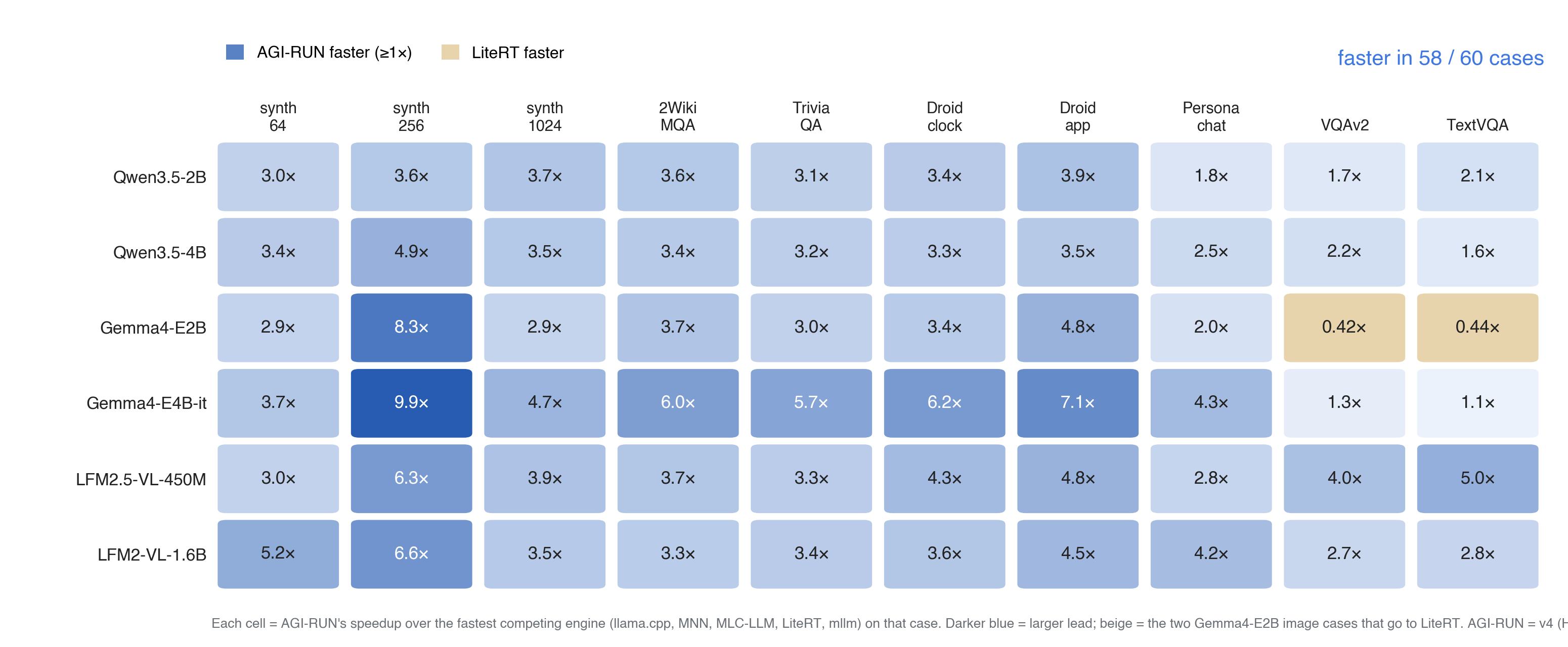
Where LiteRT is faster. Two of the sixty cases go to Google's LiteRT, both on the smallest model, Gemma4-E2B, running image workloads (VQAv2 and TextVQA).
LiteRT is Google's own engine for Gemma, and Google's engineers hand-tuned a path for Gemma's per-layer image embeddings with resources few teams can match. It doesn't survive the jump to the larger Gemma4-E4B: there the same two image workloads become memory-bound, and our placement is faster again (1.3× and 1.1×).
A kernel hand-tuned for one configuration beats us on exactly that configuration, and nowhere else.
An on-device agent runs against a latency budget: the user waits only so long for it to act, and everything the agent reads has to fit inside that window. Model throughput sets the ceiling on how much the agent can take in before it violates the budget.
Doubling the engine’s speed doubles the ceiling: more of the screen, action history, and state context the agent can hold. The same headroom can go to a bigger model instead: more parameters at the same wait time.
Our unique mapping allows us to hold this speed increase across six models and ten workloads. As we covered in our last post, AGI-RUN uses cost models to place each workload across the CPU, GPU, and NPU and to map memory efficiently, instead of hand-tuning a kernel per model.T
How AGI-RUN produces these numbers, the full setup and per-case data are coming soon in a technical deep dive.
Our research series on on-device AI, compilers, and edge inference.
We're hiring on-device research talent. If the problems in this post are the problems you work on, check out our open roles.